Windows配置heritrix3做网络爬虫开发实例
番茄系统家园 · 2022-04-30 03:19:03
一、引言:
最近在忙某个商业银行的项目,需要引入外部互联网数据作为参考,作为技术选型阶段的工作,之前已经确定了中文分词工具,下一个话题就是网络爬虫的选择,目标很明确,需要下载一些财经网站的新闻信息,然后进行文本计算。记得上一次碰爬虫还是5年前,时过境迁,不知道爬虫的世界里是否有了新的崛起。比较过一些之后,初步认定Heritrix基本能够满足需要,当然肯定是需要定制的了。
二、版本选择
Heritrix当前版本3.1.0,安装后发现,启动任务时,Windows平台有BDBOpen的错误(具体原因不详),Linux环境没有测试。度娘了一把,没啥实质性收获,如果从源码去看,又太费时间。就换到了3.0.5,这个版本也有问题,就是创建Job时,总是提示文件夹有问题,可以选择手动创建下载任务。操作界面如下图所示: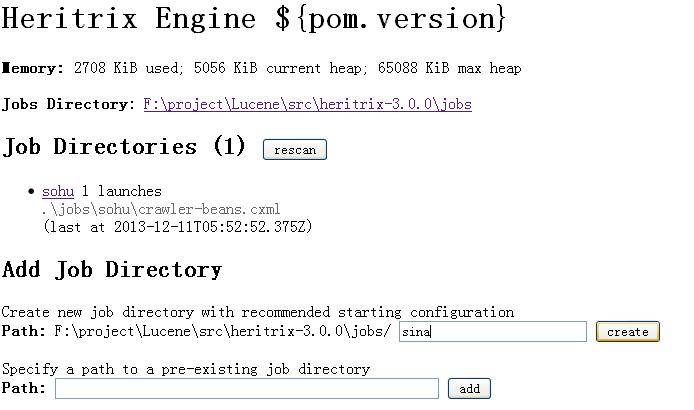
三、配置任务-手动
1.jobs目录下新建文件夹sohu;
2.拷贝模板文件profile-crawler-beans.cxml到sohu目录
3.重命名profile-crawler-beans.cxml文件为crawler-beans.cxml
4.手动修改文件crawler-beans.cxml,设置目标网站和存储方式:
复制代码代码如下:
# This Properties map is specified in the Java 'property list' text format
# a href="http://java.sun.com/javase/6/docs/api/java/util/Properties.html#load%28java.io.Reader%29"http://java.sun.com/javase/6/docs/api/java/util/Properties.html#load%28java.io.Reader%29/a/p
metadata.operatorContactUrl=http://localhost
metadata.jobName=sohu
metadata.description=sohujingxuan
##..more?..##
# URLS HERE
http://t.sohu.com/jingxuan
四、停用Robots检查
改造函数,禁用Robots协议检查,目的就不说了,改造方法如下:
复制代码代码如下:
private boolean considerRobotsPreconditions(CrawlURI curi) {
// treat /robots.txt fetches specially
//++zhangzl:取消robots.txt的强制限制
return false;
//--/p
}
五、后续工作
1.定向下载改造:只下载目标内容,过滤无关信息。
2.自动解析改造:下载内容自动解析到指定目录,指定格式。
免责声明: 凡标注转载/编译字样内容并非本站原创,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。如果你觉得本文好,欢迎推荐给朋友阅读;本文链接: https://m.nndssk.com/wlaq/155401Vm3NDI.html。



















